如果你已经知道单细胞分析大概在干什么,但准备真正推进项目,最需要的往往不是概念解释,而是一份能照着走的步骤清单。真实项目里,大家最常问的也不是“这个函数有没有”,而是“先做什么、后做什么、哪一步该停下来检查”。
这篇文章就从项目执行视角,把单细胞分析步骤完整捋一遍。
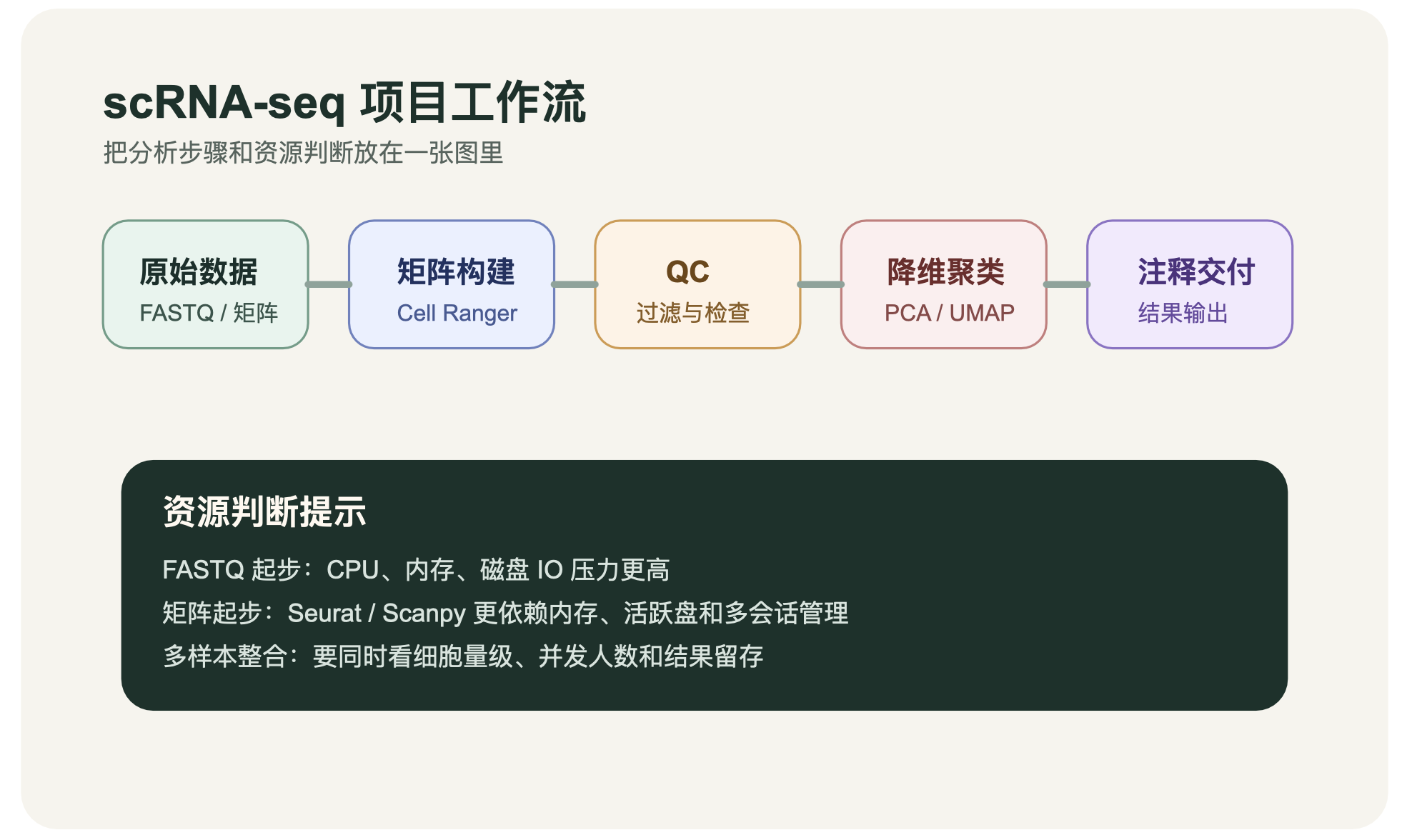
开始前先问清楚这几件事
单细胞项目之所以中途容易失控,很多时候不是分析逻辑错了,而是前期边界没说清。正式推进前,建议至少先确认:
你是从
FASTQ开始,还是直接从表达矩阵开始预计有多少细胞、多少样本,后续要不要做整合分析
结果是内部使用,还是要交付给合作方或客户
是单人使用,还是实验室或团队多人共享环境
这些信息会直接影响分析复杂度、服务器配置和存储规划。
第一步:确认项目目标和样本设计
很多项目一开始就埋雷,不是软件没装好,而是目标没说清。至少要先确认:
这次是想识别细胞类型,还是比较处理前后变化
是单样本探索,还是多样本对比
是否涉及疾病组和对照组
后面需不需要做细胞通讯、轨迹分析或亚群深挖
这些问题会决定你在注释、分组比较和下游分析上的重点。
第二步:准备原始数据或表达矩阵
项目起点一般就两种:
从
FASTQ原始测序数据开始从表达矩阵开始
如果是 10x 项目,通常会先通过 Cell Ranger 生成矩阵;如果是公共数据,很多时候可以直接下载表达矩阵进入下游分析。
这一段真正要检查的,不只是“有没有文件”,还包括:
文件结构是否齐全
样本命名是否一致
元数据是否同步整理
![生信分析跑不动?试试稳定高性价比的生信云 → [www.tebteb.cc]](https://www.tebteb.cc/upload/%E7%94%9F%E4%BF%A1%E5%9C%86%E6%A1%8C-kgzw.png)
第三步:做基础质控
单细胞分析步骤里,质控几乎决定了后面一半结果是不是站得住。常见检查项包括:
每个细胞的基因数
每个细胞的总 UMI 数
线粒体基因比例
是否存在明显双细胞
这一阶段最好先画图看分布,再设阈值。不同样本之间差异很大,经验值可以参考,但别机械照搬。
第四步:过滤低质量细胞和异常值
有了分布判断之后,就进入正式过滤。常见策略包括:
去掉基因数过低的细胞
去掉线粒体比例过高的细胞
排除疑似双细胞或异常高计数细胞
这一步的目标不是把数据滤得越干净越好,而是在保留真实生物学信号的前提下,把明显噪声拿掉。
第五步:标准化和特征筛选
单细胞数据在不同细胞间存在测序深度差异,所以需要标准化。标准化之后,通常还要筛选高变基因,为后续降维和聚类提供更稳定的输入。
这一段经常被新手当成例行公事,但它其实很关键。后面的结构识别,很多时候就取决于你送进去的特征质量。
第六步:降维
标准化之后,通常会先做 PCA,再基于 PCA 结果做邻近图构建和聚类。降维的意义,是把高维表达信息压缩成更容易分析的低维表示。
有一点最好提前建立:降维不是为了图好看,而是为了更稳地提取主要结构。
第七步:聚类
聚类是单细胞分析步骤里的核心环节之一。它决定了你最终会得到多少个细胞群,以及这些群体分得是不是合理。
聚类时建议重点检查:
分群是否和已知 marker 大体一致
是否出现明显由技术噪声主导的 cluster
一个 cluster 里是否混了多种差异很大的细胞类型
如果结果看起来很怪,先别急着往后做差异分析,回头检查 QC 和参数往往更划算。
第八步:细胞类型注释
这是很多项目最关心的一步,因为只有注释完成,后面的生物学解释才算真正开始。
常见注释方法包括:
手动查 marker gene
结合已发表文献
借助参考数据库或自动注释工具
经验上,更稳的方式通常是“自动工具先初筛,人工再复核”。效率和可靠性之间会更平衡。
第九步:分组比较与差异表达分析
注释完成后,很多项目会进入比较阶段,例如:
疾病组和对照组中,同类细胞的差异表达
某个细胞亚群内部的状态变化
不同 cluster 之间的 marker gene 比较
这一步很容易踩到一个坑:只按细胞数比较,不看样本来源。样本结构和生物重复会直接影响结果解释强度。
第十步:下游分析
根据研究目标不同,常见下游分析包括:
GO / KEGG 富集分析
GSEA
细胞通讯分析
拟时序或轨迹分析
转录因子调控分析
一个常见误区是分析越做越多,但每一块都很浅。真正有价值的项目,通常是围绕核心问题往下挖,而不是图越多越好。
第十一步:结果输出与项目交付
一套像样的单细胞分析,最后不只是发几张 UMAP 图,而是要整理出可复核、可追踪、可继续使用的交付内容。
建议至少包含:
样本信息和分析说明
QC 图和过滤标准
聚类和注释结果
marker gene 表
差异表达结果表
关键可视化图
分析脚本和版本记录
如果是商业服务、合作项目或论文支持,这一步尤其不能省。
单细胞分析步骤里最容易被忽视的三件事
1. 元数据整理
很多后续混乱,源头都在前面样本命名、分组标签和批次信息没整理好。
2. 参数记录
尤其是做多轮尝试时,如果没有记录 QC 阈值、分辨率和 PC 数量,后面很难复现。
3. 结果解释
单细胞分析不是把软件输出贴到 PPT 上就结束。真正重要的是,你能不能结合课题背景回答“这个结果说明了什么”。
单细胞分析步骤常见问题
单细胞分析步骤一定固定吗
主线通常比较稳定,但具体顺序和细节会随着数据起点、样本设计和研究目标调整。
单细胞分析先学流程还是先学 Seurat
建议先学流程。流程清楚之后,再看 Seurat 会更容易理解每一步为什么存在。
单细胞分析项目什么时候要开始考虑服务器
只要数据规模、样本数或并发使用开始上来,就应该提前评估。不要等报错、爆内存或多人抢资源了才回头补。
结语
单细胞分析步骤看起来很多,但真正串起来以后,本质上就是一条很清楚的链路:从原始数据出发,先控制质量,再识别结构,最后完成注释和解释。只要前面几步做得扎实,后面的结果通常不会太离谱。